We are happy to share that the first preprint of the MIDOG 2025 challenge paper is now available at this link: http://arxiv.org/abs/2606.07368
The most interesting results from this third iteration of the successful MIDOG challenge are:
- Performance of automatic mitosis detection models collapses outside curated hotspot regions. Evaluating in random and challenging (rich in imposters) regions more than tripled the false positive rate (increase of 208%), exposing a clinical reliability gap.
- Biological diversity reveals blind spots. Across 365 cases and 12 human, canine, and feline tumor types, top teams hit 0.740 F1 (detection) and 0.908 balanced accuracy (atypical classification) — but mitosis detection consistently underperformed on rare and highly pleomorphic tumors.
- Ensembling helps, TTA does not. Model ensembling gave consistent gains (average increase of 1.5 percentage points in overall F1, 1.3 percentage points in overall balanced accuracy); test-time augmentation produced no meaningful improvement.
The complete paper can be found on arxiv and was recently submitted to a leading journal in the field.
A brief overview of the MIDOG 2025 challenge
The main task of the MIDOG 2025 challenge is to detect mitotic figures (depicting cells that are dividing) in tumor tissue. This is a prime marker for tumor aggressiveness and used in clinical routine for many tumors. MIDOG 2025 evaluates the performance of algorithms on unseen domains – i.e., previously unknown tumor types, where no data is (to the best of our knowledge) publicly available.
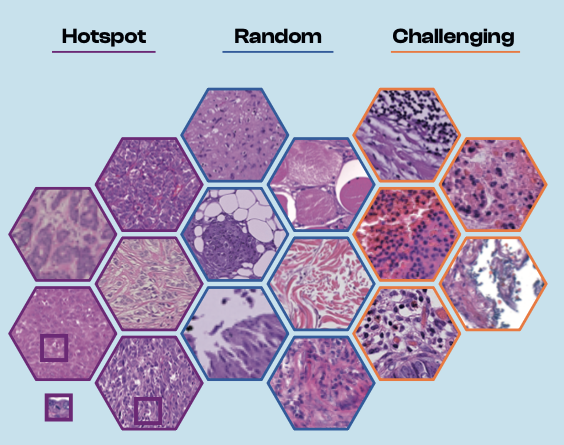
Moreover, since the 2025 edition, we also do not only evaluate on hotspot regions (areas of high mitotic density) but also on random areas – and even on areas that are known to be challenging for algorithms. The total dataset encompasses 365 cases, spanning approximately 750 square millimeters of tissue.
To sum it up: It’s the most diverse dataset you can find today for this task. We evaluated a suite of algorithms on this in the MIDOG 2025 challenge.
Many algorithms worked fine in the hotspot area, but not in random/challenging areas
We experienced a marked drop when evaluating outside of hotspot regions:
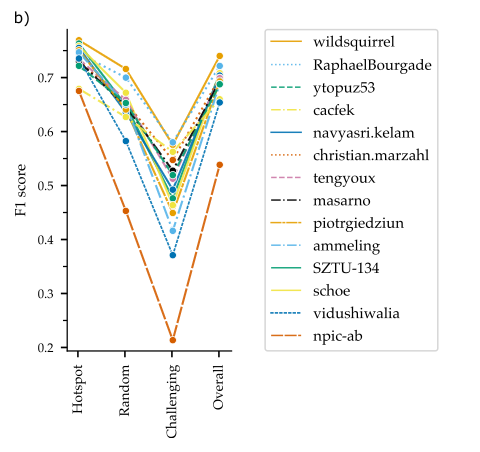
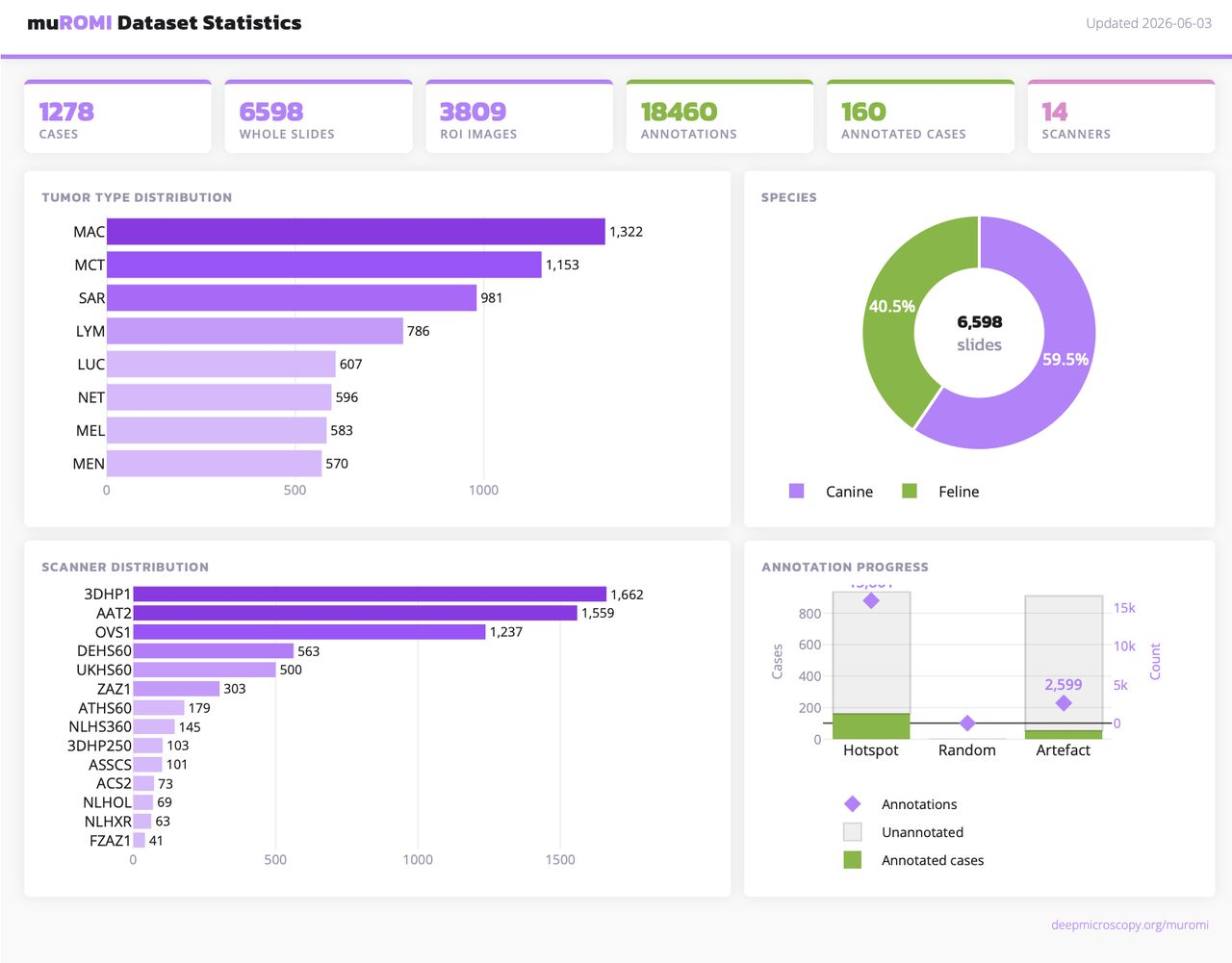
This indicates that there is more diverse data necessary to train more robust detectors. We are working on exactly that in our muROMI project. If you are interested about the current state of curation and annotation, please have a look at our dashboard.
Ensembling helped, TTA did not
We wanted to find out the magnitude of commonly used machine learning tricks like ensembling and TTA, that are known to be working well, but similarly increase runtime significantly. We ran a complete ablation study of all our submissions where the docker containers were available and where participants used either of these methods:
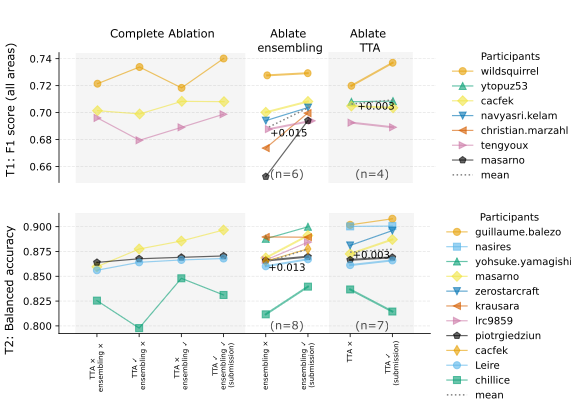
As our investigation shows, the effect of TTA was mostly negligible overall, but ensembling provided a measurable improvement of around 1.3 to 1.5 percentage points in the overall metric.


Comments are closed